|
|
|
|
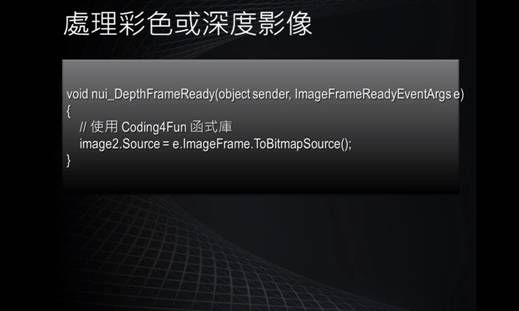
Kinect簡介: 首先,Kinect機身上有3顆鏡頭,一次可擷取三種資訊,分別是彩色影像、3D深度影像、以及聲音訊號。 中間的鏡頭是一般常見的RGB彩色攝影機,用來錄製彩色圖像,也就是辨識玩家身分(靠著人臉辨識和身體特徵)、以及辨識基本的臉部表情。解析度為1280*960。 左右兩邊鏡頭則分別為紅外線發射器和紅外線CMOS攝影機所構成的3D深度感應器,用來擷取深度數據(場景中物體到攝影機的距離),Kinect主要就是靠3D深度感應器偵測玩家的動作。解析度為640*480。 同時Kinect還搭配了追焦技術,底座馬達會隨著對焦物體移動跟著轉動。而轉動的角度為左右各27度。 Kinect也內建陣列式麥克風(Microphone Array),由四個麥克風同時收音,比對後消除雜音,並透過其採集聲音,進行語音識別和聲源定位。 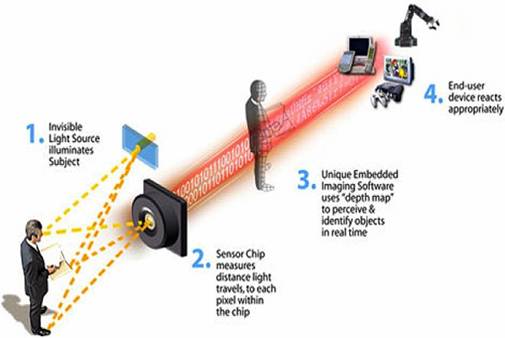 這張圖顯示了Kinect如何截取資訊。 Kinect利用紅外線發射器會發出一種不可見光來照射目標。接著,鏡頭裡的感應晶片會測量反射光所走的距離,然後進行編碼。然後,會有一種特殊內建圖片軟體來感知與辨認在真實世界中這個物體內不同點的距離。最後,終端使用者機器會有合適的回應。 彩色影像擷取原理  首先是如何去初始化kinect的api。如果要用控制一個kinect感應器,首先,必須要去產生一個runtime物件,每個runtime物件代表所連接的一台kinect設備。那麼有了runtime物件後,接下來需要呼叫initialize這個方法,他們可以做初始化kinect設備的動作。那麼在initialize這個方法的參數裡面,可以指定要取得這個設備上的哪種資訊,看是要取得彩色影像串流,還是深度串流,還是想做骨架追蹤。接下來就可以開始使用這個runtime物件的方法或者去存取它的事件來接收這些影像資料或是骨架資料。而在應用程式關閉之前,必須去呼叫runtime物件的uninitialize來關閉這個設備,以讓接下來的應用程式可以使用這個設備。  接下來我們來看一下要如何初始化來截取彩色影像。剛剛說要呼叫initialize這個方法的時候呢,要帶一個參數,這個參數的型態是個列舉型態,叫做runtimeOptions,只要使用usecolor這個列舉值時,就會告訴它,我希望截取彩色影像這個串流。在截取彩色影像時,可以使用截取事件。也就是說,使用runtime物件有個事件,叫做videoframeready,就是當它每截取一張畫面時候呢,就會把這張畫面的圖傳送到videoframeready這個事件裡,則就可以在videoframeready這個事件裡來處理這張圖片。接下來要去命令kinect開始來截取這樣的串流。所以要透過runtime物件裡有個屬性叫做videostream,就是影像串流,來open這樣的串流。而在open這個串流時,需要帶一些參數。第一個參數是影像串流的類型,剛剛講的就是video是彩色影像。第二個參數是緩衝區數量,可以1到4,如果電腦運算能力比較強,可以用1或2。如果運算能力較差,可以使用4,以免到時候影像來的速度比處理速度還來的快時,可以有4個緩衝區來存取這四個像。第三個參數是想要截取的串流影像的解析度,而彩色影像可以高達一千多乘以一千多。最後一個參數是imagetype,就是想要取得影像的格式,也就是傳回來的影像格式的編碼方式,這裡是使用RGB的方式,就是彩色的影像。  剛剛講了有一個事件,叫做videoframready,在這個事件裡,有一個參數的屬性叫做imageframe,就是所有傳回來影像的畫格,而在imageframe裡有一個屬性叫做image,它的型態是planarimage,就是點陣圖,但是這點陣圖不是我們熟悉的bitmap物件,所以想要轉換的話,要做一些處理。使用coding4fun的函式庫比較方便,透過imageframe有一個擴充方法,叫做ToBitmapsource,就可以轉換了。 下圖為彩色影像擷取結果: 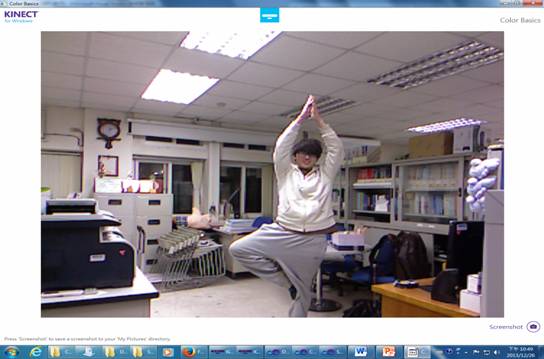 深度影像擷取原理 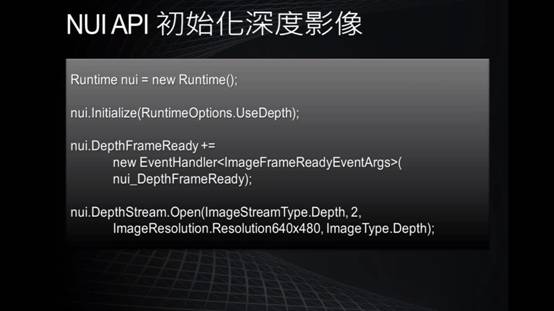
深度影像擷取之原理與彩色影像基本上幾乎一模一樣。只不過,runtime物件裡的事件,要換成depthframeready,則深度資料就會在depthframeready這個事件裡處理。還得要透過runtime物件裡有個屬性叫做 depthstream,就是深度串流,來open這樣的串流。Depthstream裡的參數和彩色影像擷取的概念是相同的。 同樣地,需要ToBitmapsource這個擴充方法來轉換。下圖為深度影像擷取結果: 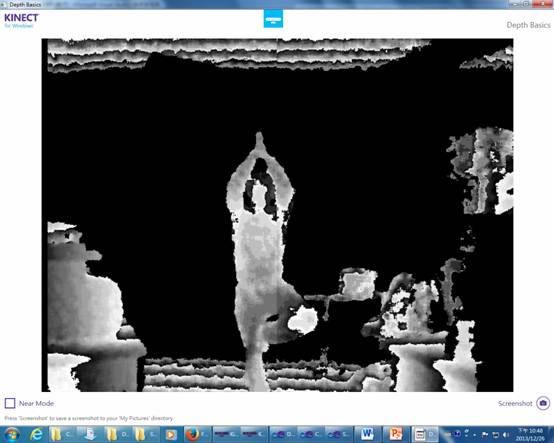 骨架追蹤原理 首先,骨架追蹤是由3D深度圖像轉為骨架追蹤系統,透過Light Coding技術所獲得的只是基本的影像資料,重點還是要辨識影像,轉換為動作指令。Kinect可同時辨識6人,包含2人的動作追蹤,每人能追蹤20個點,包含軀幹、四肢以及手指等。我們在初始化NUI啟動骨架追蹤時,指定Kinect系統追蹤要使用的骨架資料,因此傳回的不是點陣圖,而是這些座標的集合,因此不用再去算座標對應動作。我們大部分的動作偵測都是由判斷式所構成。例如:右手舉高。抓取右手Y座標關節,判斷是否高於頭Y座標,若有,則為右手舉高。如此,各個複雜的動作,都可藉由此相對位置的判斷式寫出動作偵測。
|
|
|